
Ubuntu Gnome 13.04
Finalmente dopo tante versioni di Ubuntu con Unity integrato,...

Ubuntu installazione Filezilla
Per tutti coloro che creano siti web hanno bisogno di un client FTP in grado di...
Ubuntu Tweak
L'installazione di questo programma per cambiare e modificare il DE di ubuntu ma non solo. E...
W.I.N.E. installazione
Un programma che su Linux non può mancare è sicuramente W.i.n.e.(Wine Is Not an Emulator)
Spotify per Ubuntu
Spotify è il nuovo servizio per ascoltare la musica in streming totalmente gratis scaricando...

Ubuntu 12.04 - TV RAI - Firefox
Utilizzando Ubuntu 12.04 è possibile visualizzare i canali Rai? Per la visualizzazione...

W.I.N.E. - World of Worcraft - Pandaria
Installiamo il più bel prodotto Blizzard sul nostro Ubuntu attraverso WINE.

W.I.N.E. - Diablo 3
Un altro bellissimo gioco della Blizzar è sicuramente Diablo 3 si può installare con Wine in...
Ubuntu 12.04 Tetheing IPhone 4s
Questo tutorial serve per utilizzare il nostro IPhone come modem, ormai le...





Ubuntu 12.04 - OCR documenti con Tesseract
- Dettagli
- Categoria: Ubuntu
- Pubblicato Lunedì, 06 Aprile 2015 07:58
- Scritto da Super User
- Visite: 4015
![]()
È possibile prelevare da un immagine il testo contenuto in essa con Ubuntu?
Quali programmi ci occorono per eseguire la conversione?
Per poter estrapolare dall' immagine il testo che vi è presente bisogna utilizzare la tecnologia OCR (Optical Caracter Recognition), che consente di riconoscere i caratteri dell' immagine e di poterli utilizzare come testo editabile e quindi modificabile.
In questo modo e possibile estrapolare da documenti cartacei digitalizzati dallo scanner quello che ci serve senza avere il peso dell' immagine.
Analizziamo i programmi che ci servono per questa operazione il programma «Tesseract-ocr» prelevabile dai repository di ubuntu ch'è il vero motore di tutto; «Xsane» programma per l'aquisizione dello scanner, «gImageReader».
Prima fase scarichiamo dai repository di Ubuntu Tesseract, imagemagick e xsane: si può utilizzare la parte grafica utilizzando il gestore di pacchetti oppure attraverso il terminale
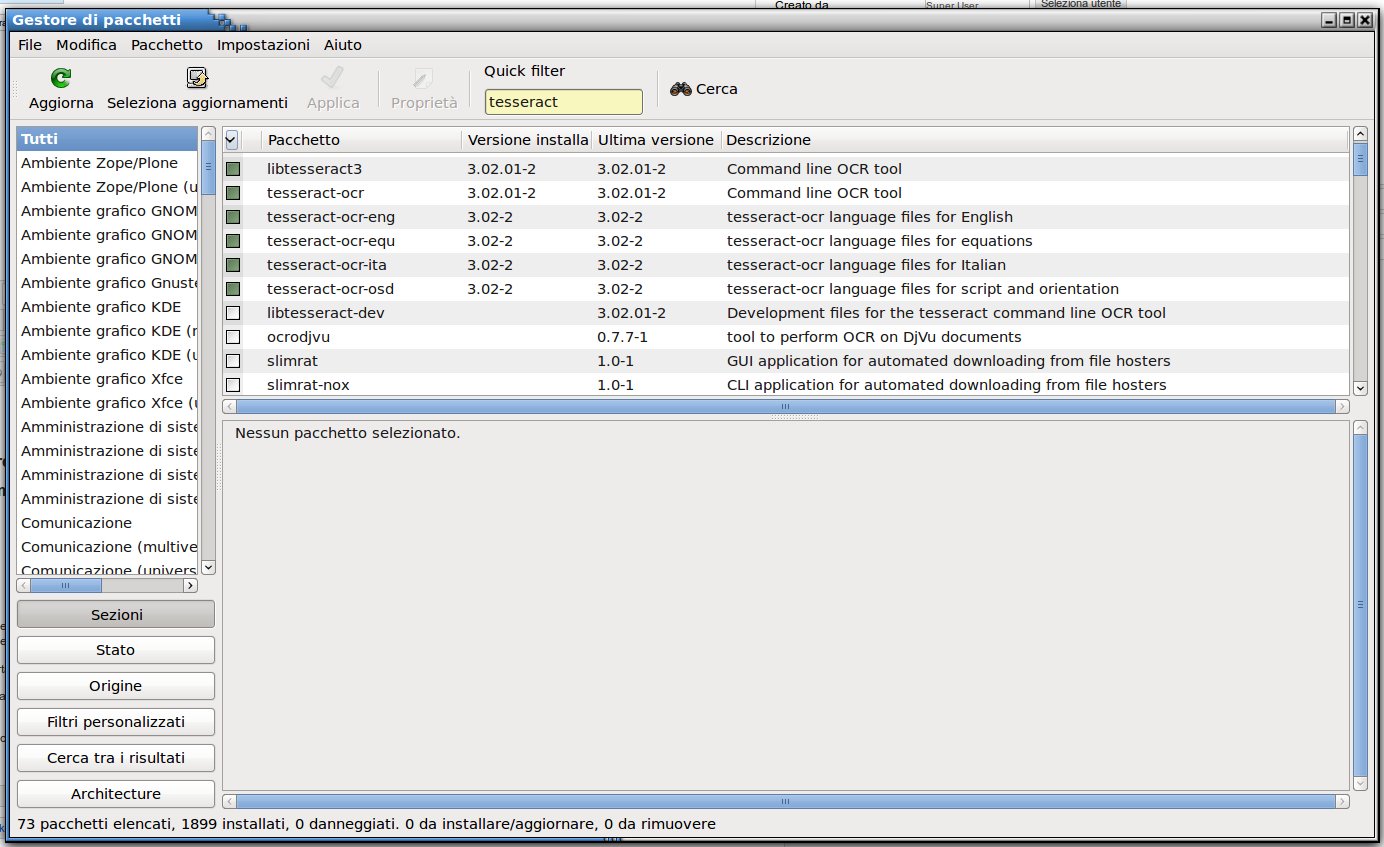
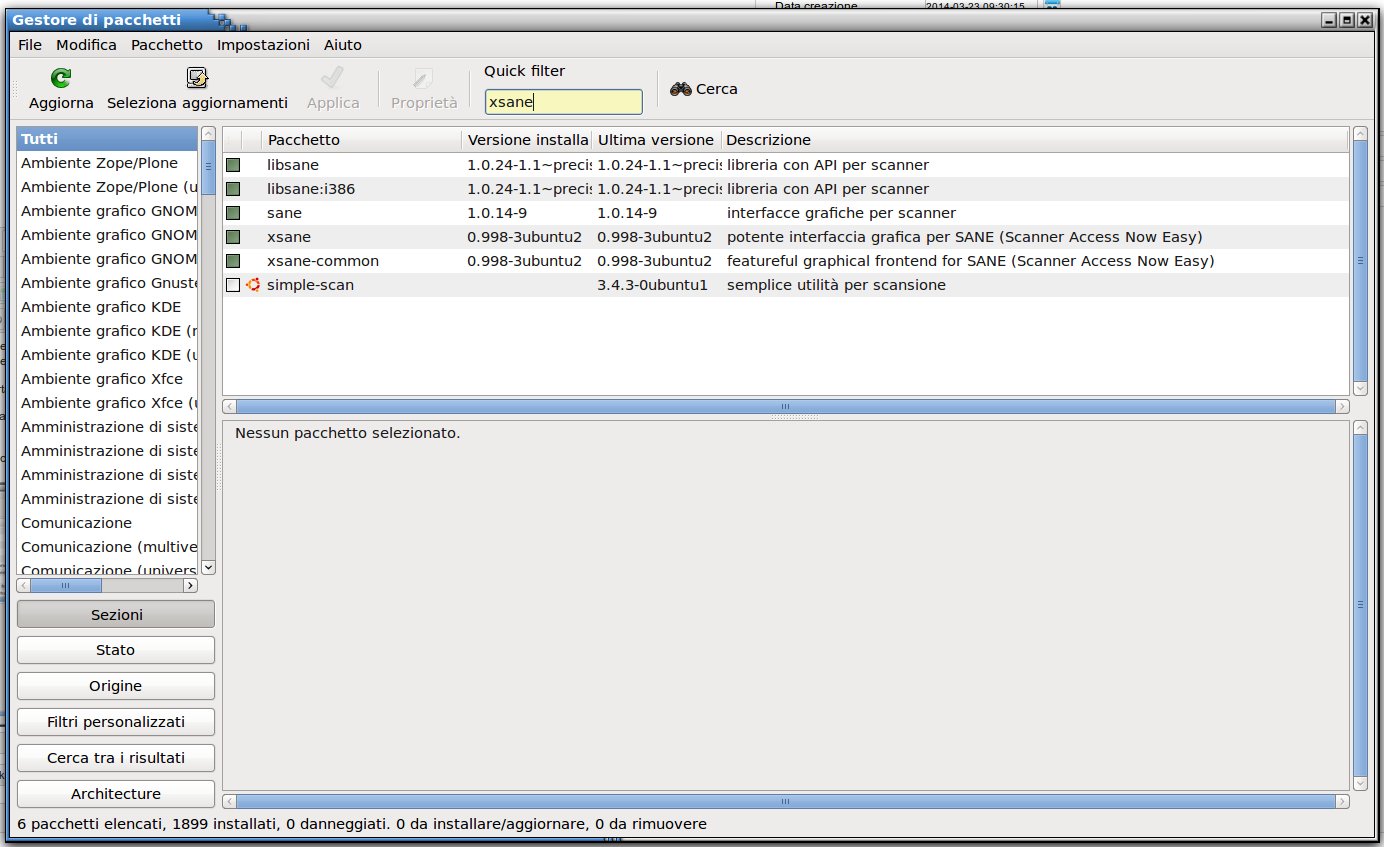
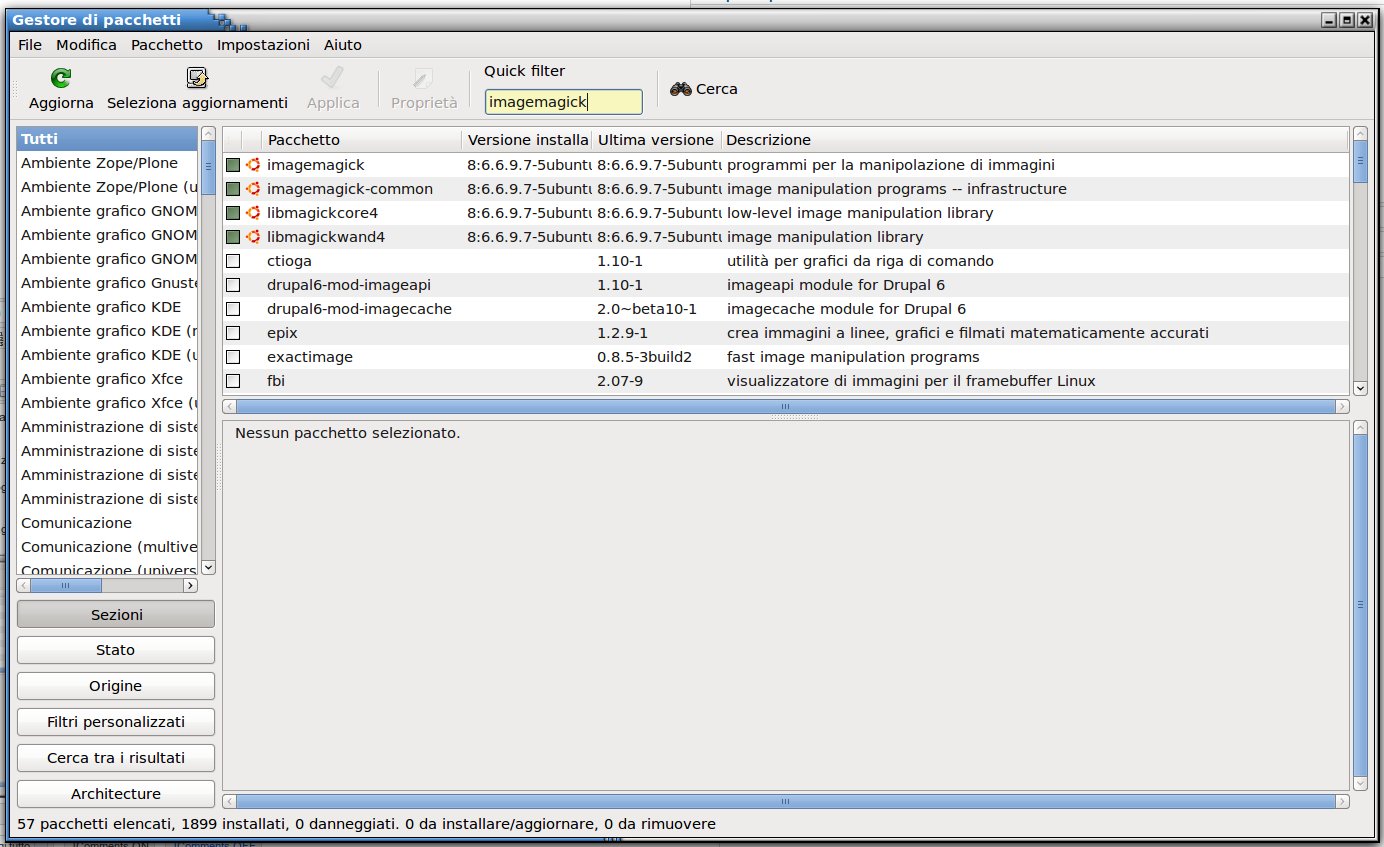
attraverso il terminale è più semplice, aprite il terminale utilizzando la combinazione di tasti «Ctrl + Alt + T» scrivete «sudo su» e digitate la password (non si vede mentre scrivete per ragioni di sicurezza) poi selezionate la riga sottostante o riscrivetela.
apt-get install tesseract-ocr tesseract-ocr-ita xsane imagemagick
Parte Due preleviamo l'interfaccia grafica gImageReader dall'indirizzo di sourceforge.net scarichiamo il file Deb e lo installiamo all'interno del sistema o attraverso Gdebi oppure attraverso il terminale in questo modo
wget -O gimagereader_0.8.1-1_all.deb http://sourceforge.net/projects/gimagereader/files/0.8.1/gimagereader_0.8.1-1_all.deb/download
dpkg -i gimagereader_0.8.1-1_all.deb
apt-get -f install; rm gimagereader_0.8.1-1_all.deb
Per i nuovi aggiornamenti di tesseract si può utilizzare il repository si Sandro Mani
add-apt-repository ppa:sandromani/gimagereader
apt-get update
apt-get install gimagereader tesseract-ocr tesseract-ocr-ita
troverete l'applicazione nel menu «Grafica»
Abbiamo praticamente finito i programmi che ci servono sono presenti allinterno del computer e vediamo come utilizzarli.
Apriamo il programma Xsane per una scansione della pagina e settate il formato immagine in «TIFF», la risoluzione a 600 almeno, e il formato binario come nella foto sotto e poi premete «Acquisisci»

Carichiamo l'immagine all'interno di «gimagereader» settiamo il riconoscimento italiano o della lingua che v'interessa, selezioniamo il testo che vogliamo convertire e premiamo il tasto «riconoscere selezione»
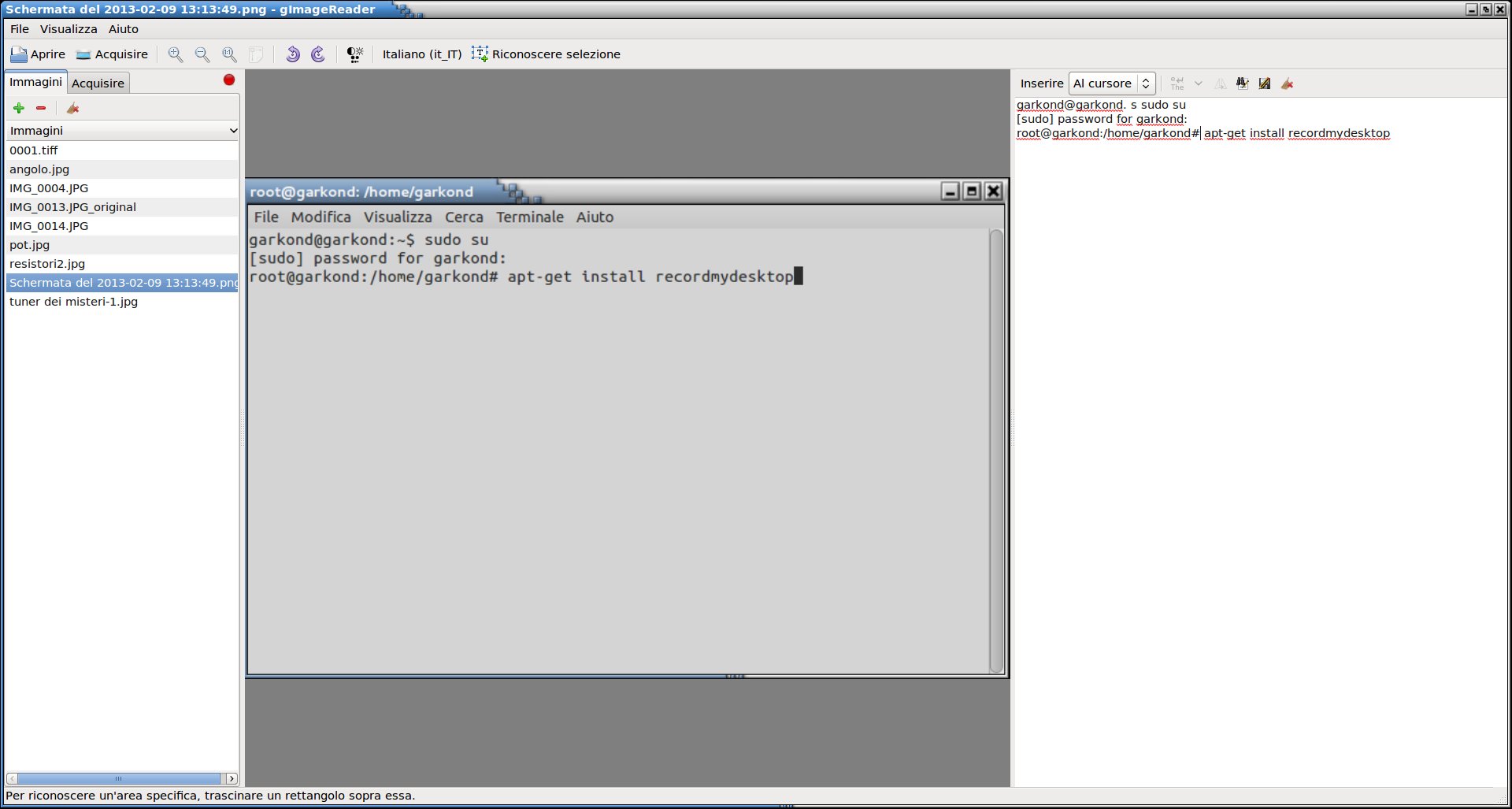
Si vedra sulla destra il testo selezionato che si puo salvare oppure copiare in qualche documento